Oracle Business Intelligence Repository Tuning
Here I disuses The following are the few things:
Designing the OLAP data model -> Tuning of the database -> Design of the repository
- The most important thing is obviously the data model. Typical OLAP systems are mostly De-normalized, preferably star schema.
- The next important thing is that your database should be tuned to OLAP requirements.
- The design has to take care of the loading mechanisms because a typical system can be optimized for a set of requirements. A system optimized for running huge analytical queries will not be good for the loading process and sufficient care has to be taken while designing the ETL process.
- Proper load calculations should be done from time to time to take care of the increase in load as the system mature.
- Bench marking the system at a particular point is required so that the same can be compared during problematic time.
The 3 steps mentioned in the above ladder are the base of an efficient system. Apart from the above steps a constant monitoring and change of strategy is required to meet the increasing requirements and load shift. Below ladder briefly mentions the important steps for this
Performing the DBA activities and scheduling it to benefit system performance -> Tuning of the repository -> Load distribution and planning -> Presentation server reporting strategy
We are trying to talk broadly about the repository tuning here.The following are the topics which are worth considering
Fragmentation is a process in which we advice the BI server to pick a particular table to satisfy a specific type of request. Aggregate tables are a subset of fragmentation where we advice the BI server to use a set of tables.
We can either configure aggregation tables separately or can use the aggregation persistence wizard of OBIEE which would create scripts for the creation of aggregate tables and configure them in the repository. Aggregation is an extended functionality of caching.
Cache can be managed at both the presentation server level and the BI server level. An intelligent cache management strategy can have serious impact on system performance.
BI server query cache: BI server saves the query result set on the disk and fulfills the request from this result set. This result might become stale with updates on the database and hence it is important to sync the cache management strategy with the load of OLAP database from ETL processes.
Various mechanisms like event pooling tables, disabling the cache for physical tables, manually removing the cache entries and using ODBC-extension functions (which provide a lot of liberty for programming cache management) can be used for cache management of BI server.
Cache seeding is an important mechanism to load the cache with the result set so that subsequent queries will hit the cache instead of the database. It is important to note that if a cache hit will happen if the subsequent query requires a subset of the query in the cache.
So it is an intelligent step to seed the cache with no filters selected. Delivers are one of the better options to seed cache because they can be scheduled at off peak hours.
Apart from the query cache in the BI server, there is a html cache in the presentation server. This cache also holds the charts that are generated in the result. These are sufficient parameters that can be configured in instanceconfig.xml file for this cache
1. Fragmentation:
Fragmentation is a process in which we advice the BI server to pick a particular table to satisfy a specific type of request. Aggregate tables are a subset of fragmentation where we advice the BI server to use a set of tables.
2. Aggregation:
We can either configure aggregation tables separately or can use the aggregation persistence wizard of OBIEE which would create scripts for the creation of aggregate tables and configure them in the repository. Aggregation is an extended functionality of caching.
3. Cache management
Cache can be managed at both the presentation server level and the BI server level. An intelligent cache management strategy can have serious impact on system performance.
BI server query cache: BI server saves the query result set on the disk and fulfills the request from this result set. This result might become stale with updates on the database and hence it is important to sync the cache management strategy with the load of OLAP database from ETL processes.
Various mechanisms like event pooling tables, disabling the cache for physical tables, manually removing the cache entries and using ODBC-extension functions (which provide a lot of liberty for programming cache management) can be used for cache management of BI server.
Cache seeding is an important mechanism to load the cache with the result set so that subsequent queries will hit the cache instead of the database. It is important to note that if a cache hit will happen if the subsequent query requires a subset of the query in the cache.
So it is an intelligent step to seed the cache with no filters selected. Delivers are one of the better options to seed cache because they can be scheduled at off peak hours.
Apart from the query cache in the BI server, there is a html cache in the presentation server. This cache also holds the charts that are generated in the result. These are sufficient parameters that can be configured in instanceconfig.xml file for this cache
4. Strategy to use the connection pools:
Conn pools reduce the overhead of connecting to the database for every new request and also allow multiple concurrent requestsWe must calculate the sessions that we will allow for a particular connection pool because if this threshold is reached and other connection pools to the same data source are not available then the users will have to wait for getting their requests handled.
Again if this is set at a very high value then it might overload the underlying database and also of the BI server.
Since the time required for logging in the application is the most important metric to judge an application’s performance and since many initialization blocks are used during logging in so it is always advisable to have a separate connection pool for all the initialization blocks.
We can use the permissions tab to streamline the users who would use a particular connection pool. This feature can be used to dedicate a connection pool to privileged users
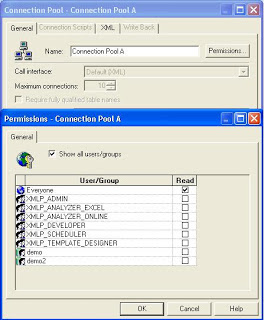
Again persist connection pool property can be used to perform generalized subquery which can reduce the data movement between BI server and database. Again there is more than 1 thing to consider before using this property
Again persist connection pool property can be used to perform generalized subquery which can reduce the data movement between BI server and database. Again there is more than 1 thing to consider before using this property
No comments:
Post a Comment